Nezávislosť dvoch premenných na sebe môžeme merať pomocou Chí kvadrát štatistiky.
Chí kvadrát (Chi-Square – χ2)
Chí-kvadrát test sa používa na porovnanie distribúcie kategorickej premennej v skupine (pozostávajúcej z kategórií, napr. druh vzdelania, rodinný stav, fajčiar/nefajčiar, atď.) s distribúciou v inej skupine. Ak sa distribúcia kategorickej premennej v rôznych skupinách príliš nelíši, môžeme konštatovať, že distribúcia kategorickej premennej nesúvisí so skupinami. Alebo môžeme povedať, že kategorická premenná a skupiny sú nezávislé. Napríklad, ak je medzi mužmi viac fajčiarov ako medzi ženami, je väčšia šanca nájsť fajčiara medzi mužmi ako medzi ženami. V tomto prípade môžeme konštatovať, že pohlavie nie je nezávislé od toho, či ide o fajčiara alebo nie (čiže existuje tu závislosť). Ak existuje rovnaká šanca, či niekto fajčí alebo nie medzi mužmi a ženami, zistíme, že šanca na pozorovanie stavu je rovnaká bez ohľadu na pohlavie a môžeme uzavrieť ich vzťah ako nezávislý.
Chí kvadrát je založený na porovnávaní pozorovaných (nameraných) – empirických početností (observed count) s očakávanými početnosťami (expected count). Očakávaná početnosť by platila pre bunku vtedy, ak by platila nulová hypotéza o nezávislosti, teda ak by boli premenné úplne nezávislé.
Tento test sa používa ako test nezávislosti pri overovaní hypotéz:
- H1: Nezávislé (bez vzťahu),
- H0: Nie je nezávislá (existuje vzťah).
Test chí kvadrát by sa nemal používať, ak viac ako 20% polí má očakávanú početnosť menšiu ako 5 a minimálna očakávaná početnosť nesmie byť menšia ako 1 (Rabušic, Soukup, Mareš, 2019, str. 261). V prípade, že nie je dodržaná podmienka o očakávanej početnosti menšej ako 5, sa odporúča použiť Fisherov exaktný test (Fisher’s exact test).
PRÍKLAD – TEST NEZÁVISLOSTI (Chi-Square Test of Independence):
Zadanie:
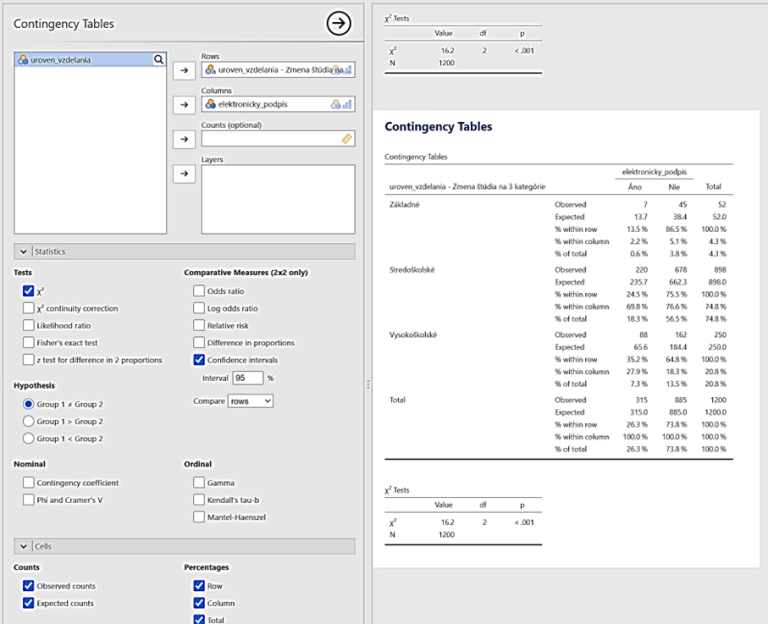
Zistite, či existuje vzájomná súvislosť medzi úrovňou vzdelania a aktivovaním si elektronického podpisu v občianskom preukaze.
Riešenie:
Pre skúmanie týchto dvoch premenných si stanovíme hypotézu na základe predpokladu, že ľudia s vyšším vzdelaním budú mať väčšiu tendenciu k používaniu informačných technológií ako ľudia s nižším vzdelaním. Budeme predpokladať, že existuje vzťah medzi úrovňou vzdelania a počtom aktivovaných elektronických certifikátov v občianskych preukazoch.
H1: Úroveň vzdelania súvisí s tým, či je alebo nie je aktivovaný elektronický certifikát v občianskom preukaze.
H0: Úroveň vzdelania nesúvisí s tým, či je alebo nie je aktivovaný elektronický certifikát v občianskom preukaze.